Table of Contents
Where it started: Meet Sarah
Three months ago, Sarah joined your contact center as a new agent. From the day she started, you had a good feeling about this hire. Manual evaluations backed it up: she was ahead of her cohort, picking things up fast, asking the right questions. You weren’t worried about Sarah.
Then one morning, a report lands on your desk. Your AI-driven quality management engine has flagged a cluster of Sarah’s recent calls. Low engagement. Missed disclosures. Overall score: 62%. Recommended action: empathy coaching.
Within hours, Sarah submits a score dispute. She doesn’t agree with the rating, and honestly, neither do you. That 62% doesn’t describe the agent you’ve been watching grow over the past twelve weeks.
So you decide to dig in; maybe the AI caught something you missed. Maybe Sarah has been struggling in ways that don’t show up in a weekly check-in. But you also know that if the score is off — even slightly — the damage is real. A new agent who is genuinely trying, getting flagged for remediation three months in? That doesn’t feel like development. That feels like a warning. And that kind of signal, left unexamined, is how you lose someone you spent months recruiting and onboarding.
Your findings are disturbing. This isn’t an accuracy problem; it’s worse. The AI did exactly what it was designed to do — and still got it wrong. You uncover three gaps.
Root cause: Three gaps. Three wrong conclusions.
The model wasn’t broken. The context was incomplete.
Each gap represents data that existed somewhere in the organization, but never reached the AI that needed it to reason correctly.
Gap 1: The AI didn’t know Sarah is new
At three months in, Sarah is still learning the ropes. But the QM system has no connection to the HR system: no hire date, no cohort assignment, no ramp stage, so it applied the exact same evaluation criteria and weightings it uses for five-year veterans.
Her 62% might actually be ahead of her peers with similar start dates. The AI couldn’t tell, not because the model was weak, but because tenure data, hire date, and ramp cohort all live in a system the QM tool cannot see.
The data exists. The scoring engine simply never had access to it.
Gap 2: The AI didn’t know Sarah was exhausted
That week’s volume forecast was off by 30%. The contact center was short-staffed, and Sarah was pulled into a split shift to cover the gap. By the time the flagged calls happened, she was in hour ten of her workday.
When QM and WFM aren’t in the same context window, the WFM schedule, shift start times, overtime hours, split-shift assignments, never reach the scoring layer. Thus, the AI can read fatigue as disengagement, and flag an operational staffing problem as a personal performance failure.
This isn’t an AI problem. The WFM data exists. QM and WFM simply weren’t connected.
Gap 3: AI judged Sarah on three calls. It should have looked at hundreds.
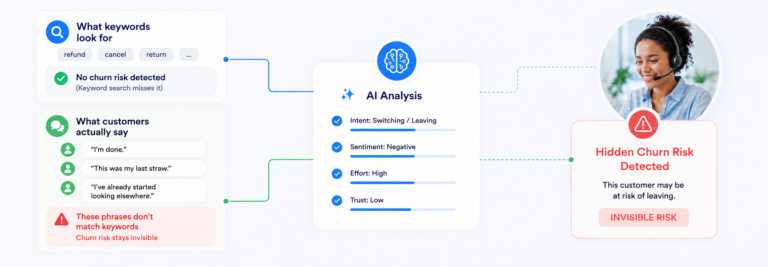
In a contact center, a single call is just a snapshot. An agent might struggle because the customer was already escalated, or because a new script went live that morning and they’re still adjusting. Put a few rough calls together and it starts to look like a pattern. But maybe it isn’t.
Now zoom out. If the system had looked at Sarah’s full history, hundreds of calls over three months, the story changes. Her hedge phrases aren’t random; they cluster around one specific policy topic. Her scores dip consistently after hour seven of a shift. That’s fatigue, not lack of skill.
In 82% of her low-scored calls, customer sentiment actually improves by the end. She’s calming frustrated customers down, consistently. The system can see that turnaround. But the improvement doesn’t always carry enough weight in the final evaluation, so the interaction still gets marked down because of how it started.
The missed disclosures tell the same story. They aren’t isolated mistakes. They began right after a script update, and the same pattern shows up across multiple agents. This isn’t an individual gap; it’s a shared adjustment issue.
That’s the real gap: scoring a few calls captures incidents. Looking across hundreds reveals patterns, and leads to completely different conclusions
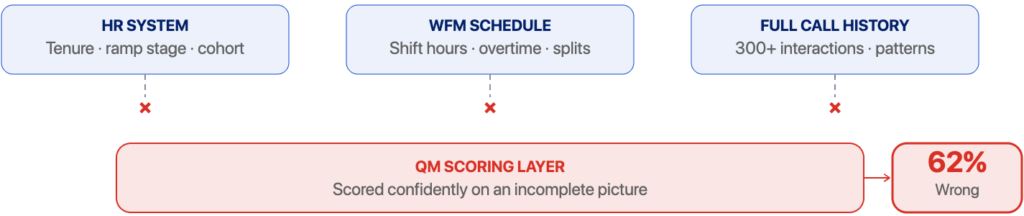
Figure 1 — Three sources of context that exist but never reached the scoring layer, producing a confident but incorrect result.
The architecture argument: Shared data layer—not a shared dashboard
The industry talks about “agentic” like it’s a feature you bolt on. Add an LLM. Add a reasoning layer. Ship it.
But Sarah’s story reveals what actually breaks: the AI reasons confidently on an incomplete picture, not because the model is weak, but because the products behind it were never designed to share context.
A shared dashboard aggregates outputs from separate systems; it doesn’t unify the inference context. SuccessKPI’s shared data foundation means every module, scoring, scheduling, coaching, real-time Agent Assist, analytics, and speech analysis, operates on a single, consistent data model. The products don’t need to be integrated because they were never separate.
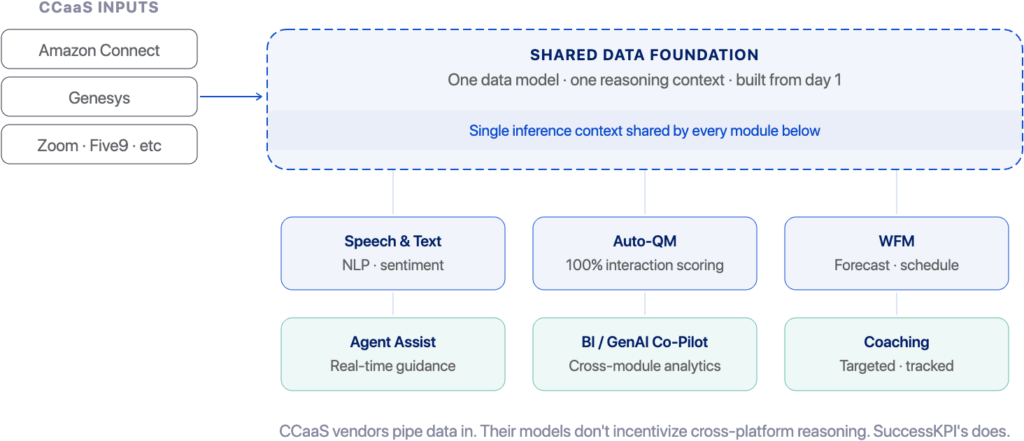
Figre 2 — SuccessKPI’s six platform capabilities — Speech & Text, Auto-QM, WFM, Agent Assist, BI/GenAI Co-Pilot, and Coaching — all built on a single shared data foundation.
The vision: From standalone AI agents to orchestrated workflows
SuccessKPI’s product strategy unfolds in two stages. First, embed purpose-built AI agents into each module — each one solving a specific, well-defined job inside the contact center. Then, connect those agents so they can work together: triggered by a single business intent and orchestrated through one unified workflow.
Both stages run on the same shared data foundation. That’s what makes the second stage achievable today — not three years from now. There’s no integration backlog to clear, no middleware to build, no eighteen-month project to connect systems that were never designed to talk to each other. The development of orchestrated, multi-module workflows is a natural extension of what’s already in production.
Each module gets its own AI agent — trained for one specific job, operating within clear boundaries, and delivering value independently. These are in production today.
Stage 1 – Purpose-built AI agents
- Auto-QM scoring Every single customer interaction gets evaluated automatically — not just a random 2–3% sample. When your quality criteria change, the AI adapts immediately. No model retraining, no engineering ticket, no waiting.
- Evaluation co-pilotAI pre-fills evaluation forms so your QA analysts don’t start from scratch. They review, adjust, and override — the AI handles throughput, humans govern the judgment.
- Deep promptsAsk questions across your entire call library in plain English. “Which agents are struggling with the new refund policy?” “What’s the top complaint this week?” Answers come from real interaction data, not dashboards.
- Real-time Agent AssistWhile agents are on a live call, the AI pulls relevant knowledge base articles, flags when customer sentiment drops so a supervisor can step in, and auto-generates the after-call wrap-up.
- WFM forecasting Uses quantile-based forecasting to predict call volume and handle times at three confidence levels: P10 (best case), P50 (expected), and P90 (worst case). Instead of staffing to a single average, you get a range that reflects real-world variability, so scheduling decisions account for both quiet days and surges.
Stage 2 – Orchestrated workflows
When purpose-built agents share a data layer, they can be chained. A single business intent triggers a Playbook — an automated, governed workflow that spans multiple modules.
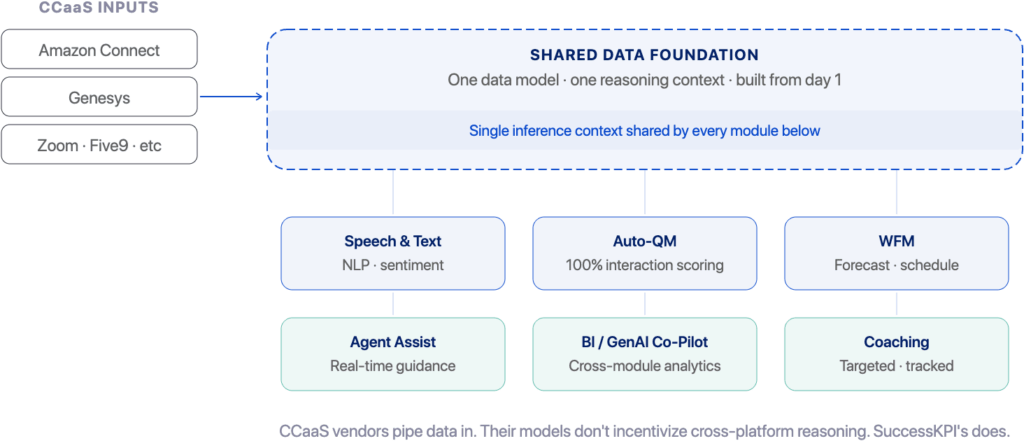
Figure 3 — Playbook orchestration: a single intent triggers a governed workflow across all six modules on the shared data foundation.
Governance model: You decide how far the AI goes
Autonomy levels are configured per step, per module — not globally. A single Playbook can mix all three levels. The AI operates exactly as far as you’ve authorised it. No further.

Figure 4 — Governance model: AI autonomy scales up as human oversight shifts from decision-making to exception-based review. Thresholds are configured per step.
The structural advantage: 2-year head start over bolt-on competitors
Many vendors are acquiring point AI solutions and stitching them together after the fact: a QM tool from one acquisition, a WFM engine from another, a coaching platform from a third. Before those pieces can reason together, there’s an eighteen-month integration backlog just to unify the data. SuccessKPI was built unified from day one, which means the orchestration layer works today, not in 2028.
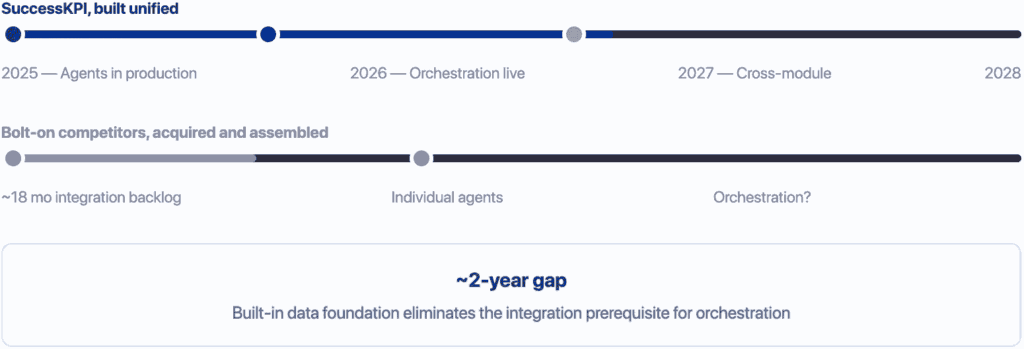
Figure 5 — Vendors assembling acquired point solutions face an integration backlog before agents can reason together. SuccessKPI’s unified architecture skips that step entirely.